This past week there were a few conversations about disaster recovery that I was involved in, and one of the interesting things I see all over is a lack of resilient system design. One server running a critical business service, and the only protection it has from any sort of disaster is a backup. We hope. That type of system design has near-zero resilience, and would look something like this:
This would be fine if the server is running a special version of Notepad++ that your team needs, but really not ideal for a Tier 1, mission-critical piece of software.
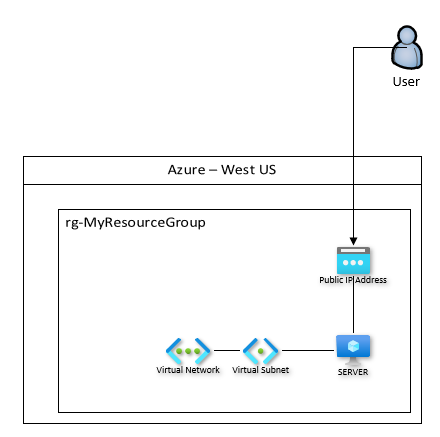
There are different ways to slice and dice the issue and solve the problem, but one of the quickest ways is to stand up a second server and toss a load balancer in front of it, like this:
In this model, you can at least patch and reboot each of these servers one-at-a time and not incur any real outage. In Azure, building out a Public Load Balancer is really quite easy to do and can be done in just a few clicks.
One nice thing about this approach is that instead of each of your servers having a public IP attached to them, the public IP is instead attached to the front side of the load balancer. So now your servers are at least not directly exposed to the internet. But…what happens if there’s a regional outage? It definitely can, and does, happen (just over a year ago a major AWS region was offline for a couple of hours).
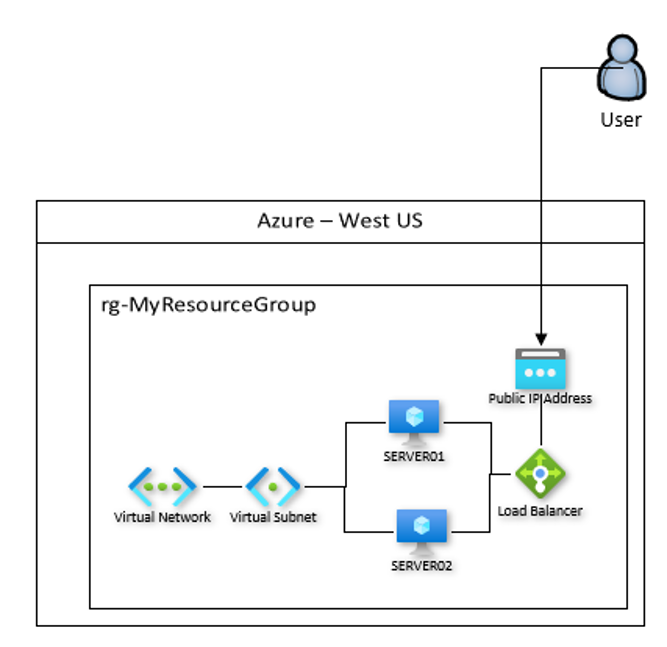
Taking this one step further would be a multi-region or globally load-balanced option, and in this case I went with a Traffic Manager profile to sit in front of a pair of load balancers:
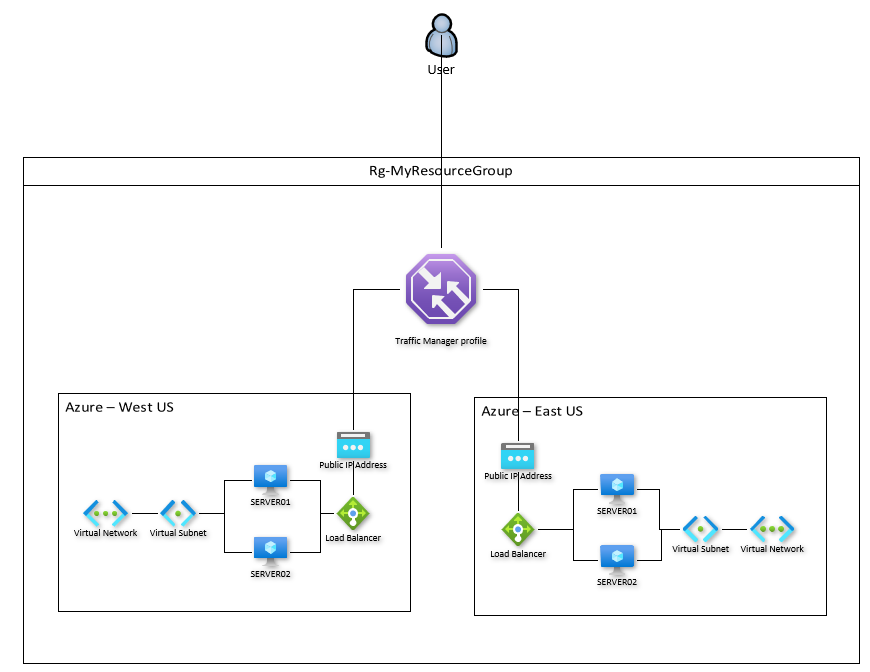
Traffic Manager profiles will balance across the Public IP Addresses of the load balancer, and does so via DNS, so you need to make sure that the Public IP Addresses have DNS names attached to them.
Building out a Traffic Manager Profile was also a pretty simple thing to do – you essentially just give it a name, attach the endpoints you want (Public IP Addresses in my case), and it starts working in seconds. Below are some tests I did with a lab environment modeled after the above diagram. I had two servers in Azure West (WESTSRV01 and WESTSRV02) and two servers in Azure East (EASTSRV01 and EASTSRV02).
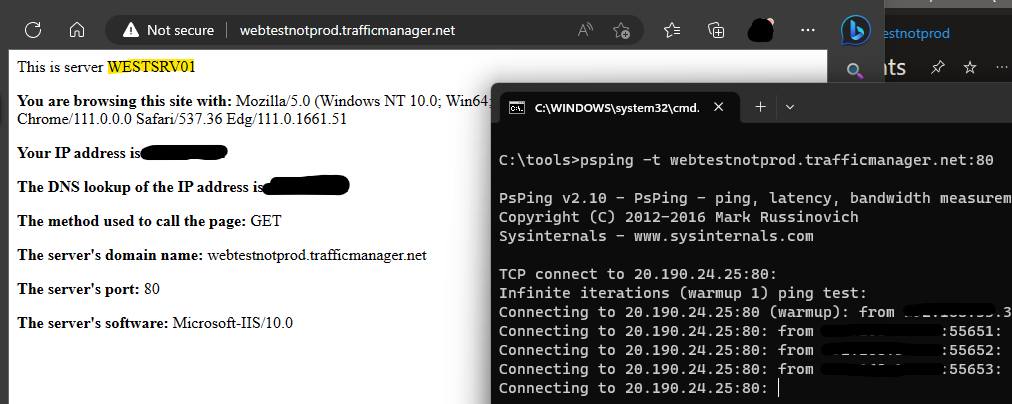
I started with a PSPING test to the public DNS name on the Traffic Manager Profile. My client resolved it to the load balancer IP for the Azure West servers, and you can see that we’ve first connected to WESTSRV01.
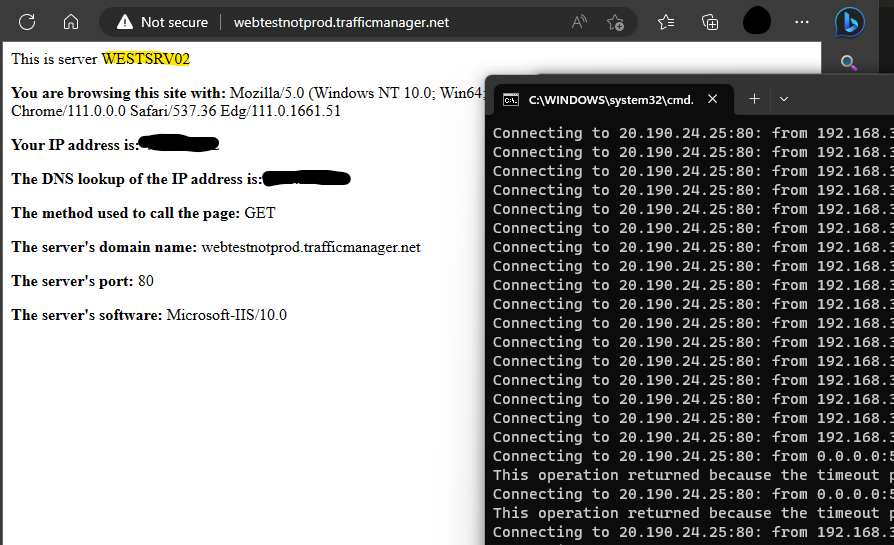
After powering off WESTSRV01, you can see we dropped two pings but the service quickly switched over to WESTSRV02. You can do some tuning on both the Traffic Manager Profile as well as the Load Balancer to tighten up the failover time for sure – in my case I used mostly defaults which, for only having two dropped pings, isn’t bad.
The next test was to shut off WESTSRV01 and watch it fail over to the pair in Azure East.
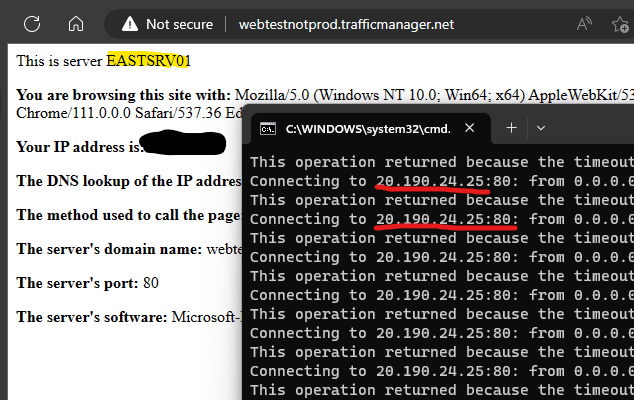
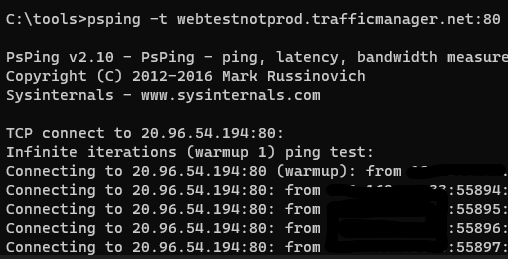
In this case, it took a few seconds for the page to refresh and show EASTSRV01, and this is almost certainly cured by tuning the health probe timeouts and such. But notice all the dropped pings? Because Traffic Manager is a DNS-based global load balancing solution, my client machine needs to resolve the DNS name to an IP address again. By stopping the PSPING tests and restarting it, we’re back to happy ping tests:
The final tests of course is to shut off EASTSRV01 and watch it roll to EASTSRV02:
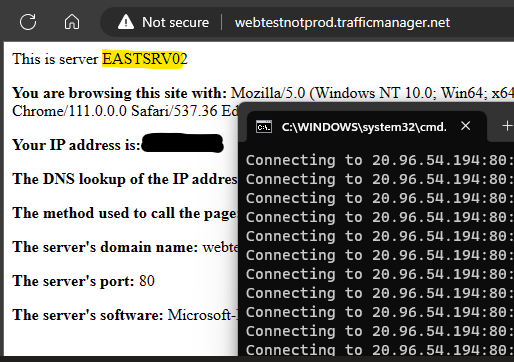
By this point in my test, three of the four servers in my lab environment are all powered off, and yet service is still available.
This was a fun lab to set up and watch. I hope to work with teams in the future to consider these types of solutions for adding resiliency to their critical servers. In recent DR exercises, I’ve seen failover times extend longer than they should. If you can build your environment to failover automatically, wouldn’t that be better? Sure, there’s costs associated with building it out, but I know I don’t want to be called at 2am on Christmas Day for a mission-critical outage…..